
Software Internationalization Problems
There's a multimillion-dollar problem in your codebase. Learn 10 problem areas needing attention when expanding internationally.

Ten problem areas in your codebase that could cost you tens of millions to fix...if you can even find them.
Consider Oracle. It spent millions fixing its code base when expanding to new countries. Might you have to do the same?
Here are ten problem areas, with examples, that can be present in any codebase. The difficult thing with these problems is that they are invisible until you expand. Moving into a new country means operating in a new 'local' in the world of software. That change can and does cause problems.
They are not easy to find nor fix. Even an assessment can run into tens of thousands of dollars.
Let's look at the problem areas:
1) Data Formatting Problems.
You aren't displaying what your users expect.
This can occur with date and time, telephone, postal, currency or general numerical data.
Time and Date
Assume you have stored the data in a format that references the time and place it is associated with and that reference can be retrieved. For example, time stored in the Universal Time Coordinate system allowing computations into local time.
You have application captureing a timestamp for the user consisting of a date and time.
If it is captured and stored as MM/DD/YYYY HH:mm:ss. How is that to be displayed?
- In the USA that would be MM/DD/YYYY HH:mm:ss
- If it was presented as above in the Netherlands -> DD/MM/YYYY HH:mm:ss
- If in Germany -> DD.MM.YYYY HH:mm:ss ( Note the . replaces / )
Time: In the USA the time is shown in a 12-hour format with an AM or PM designation. 24-hour format is more common.
Headings: How might you represent the abbreviations and representations for input guidance in a UX? In english it is MM/DD/YYYY. What are the equivalents in other languages? Have these date abbreviations been stored as column labels in the database? Are these labels displayed?
2) Static files
You use an asset appropriate for one country that is inappropriate for another.
There are two common offenders here. (There are more, but I'll focus on these.)
Image Files
For quite a while, Asana used the image of a Unicorn to celebrate completing a task in their software.
Not all cultures love the symbol of a unicorn and while we cannot know why Asana changed theirs, it is an example of a static file reference. (Even though the image is animated.) It will appear in every context regardless of the connotation.
Perhaps that is why they added other celebration icons, as is seen in this animated image on their blog.
Linked Resource Files
An easily identifiable problem relates to any legal document linked to or used in your software program.
This includes terms and conditions, cookie notices and privacy policies. They apply to a specific legal jurisdiction and cannot be assumed to apply to another.
Sidebar: There is an entire category of software products that help you manage compliance. We use and recommend Iubenda.
3) Hard-Code Strings
Your (amateur) developers hard code strings into code, not in the right place. A resource file.
This is an amazingly common error. And often features first in any list of software problems relating to international expansion.
And why shouldn't it be common?
In various forms, the very first thing taught is this code fragment:
main( ) {
printf("hello, world");
}
That's wrong.
"Hello, world" is a hard-code string. The toolsets and systems to find and fix these strings have evolved, but developers can still override the recommendations made or errors found.
4) Encoding Errors
Everything in the digital world is encoded into 1's and 0's.
Encoding is the process of mapping one form of data to another. Morse 'encoded' letters and numbers into the form of dots and dashs formed by repeatedly closing and opening an eletric circuit in a telegraph wire.
A later encoding is ASCII which allowed 128 elements of the english language to be represented by the numbers 0-127. Other encoding schemes followed, but the end result was a mapping to a number that was encoded to o's and 1's – the binary sytem used in computers.
At some point that mapped data needs to be stored in devices and the o's and 1's preserved. Problems arise when data is encoded in one format and decoded in another. The problem presents itself as jumbled characters. This can be present ina single data field, or as illustrated below, an entire web page or text within an application.
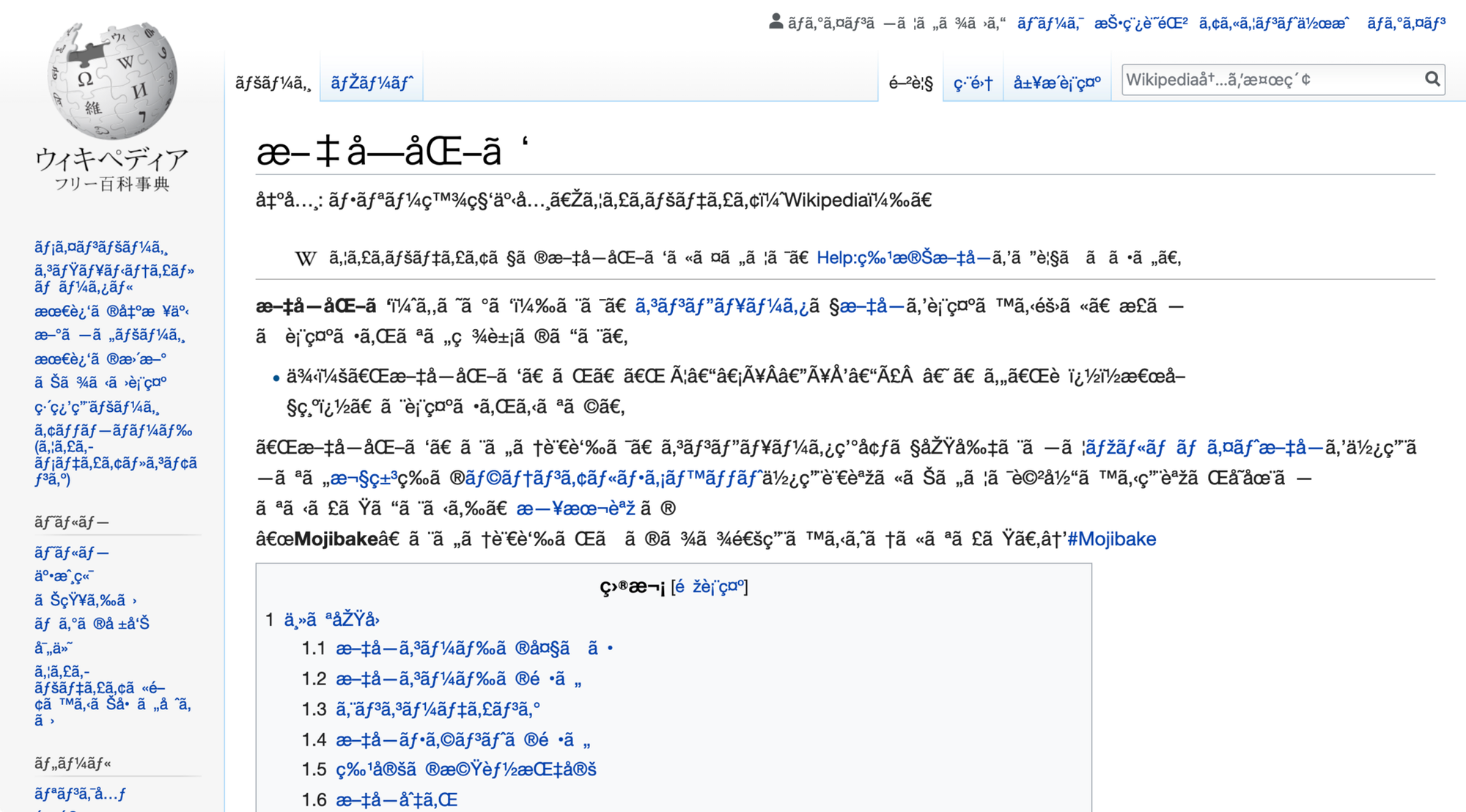
This is particularly important for multiple languages. Looking at the following list of text (strings from ChatGPT)
- English: "Hello, world!"
- Spanish: "¡Hola, mundo!"
- Chinese: "你好,世界!"
ASCII would work for english but not for Spanish. A broader encoding is needed. Unicode supplies standardized encoding for many languages and modern scripts. But we can see two examples below.
Spanish: "¡Hola, mundo!" (garbled characters due to incorrect encoding)
Chinese: "你好,世界!" (displayed correctly if the encoding supports Unicode)
5) Locale Sensitive Methods
The methods used in code and coding could change based on the localation-specific data.
What's a method? Sorting is a computational method.
Sorting errors
Let's consider a list of names to be sorted.
- Contact 1: Name - "José"
- Contact 2: Name - "María"
- Contact 3: Name - "Ça va"
- Contact 4: Name - "Élise"
- Contact 5: Name - "Anna"
Now suppose the list is sorted and displayed as follows in the app:
- "Anna"
- "Élise"
- "José"
- "María"
- "Ça va"
This is wrong. Why?
The contact name "Ça va" is incorrectly placed after "María" and before "Élise" because the sorting algorithm treats the accented character "ç" as having a higher ASCII value than lowercase letters. Similarly, "Élise" is incorrectly sorted before "José" because the accented character "é" is treated as having a higher ASCII value than unaccented characters. (From ChatGPT)
To be continued...